
How to Vibe Code with LLM's & Cursor Agents
The Optimal alpha male Workflow for DECIMATING your companies code base with Ai slop

So you’ve got some boring bullshit to do and you don’t want it to take 8 hours of coding to fix… this is the perfect use case for an LLM workflow that can automate away some of the mundane nonsense.
I’ve been working on a little workflow for these use cases and it works relatively OK, so I thought I’d share it if it helps others avoid misery, suffering and death.
You’re going to need cursor IDE if you want to try this so go ahead and download it: https://www.cursor.com/
Add stuff to give the cursor agent context following the following convention
Project Structure:
You will need the following filesproject-root/ ├── .cursor │ └── rules │ ├── entityHierarchy.mdc ←——————— file specific rule │ ├── global.mdc ←———————— this rule applies to all files │ ├── mapComponent.mdc │ ├── selectionAndFiltering.mdc │ └── variantAllocation.mdc ├── .cursorignore └── .gitignoreCursor Rules:
.cursor/rules/foo.mdcfiles have the following structure:--- description: Apply TypeScript best practices for MY_CRAP_PROJECT globs: ["**/*.ts", "**/*.tsx"] alwaysApply: true --- # TypeScript Best Practices for MY_CRAP_PROJECT Use these guidelines when writing or modifying TypeScript code in the FUBAR-agile feature: 1. Prefer explicit typing over any/unknown 2. Use type guards to narrow types safely 3. Avoid type assertions (as) where possible 4. Properly type React props and state 5. Use interfaces for objects that will be extended 6. Use type for unions, intersections, and mapped types 7. Explicitly type function parameters and return types 8. Use ReactNode for component children 9. Follow naming conventions: - PascalCase for components, interfaces, and types - camelCase for variables, functions, and methods - UPPER_CASE for constants 10. Prefer optional chaining and nullish coalescing over manual null checks 11. Use ReadOnly or Readonly<T> for immutable data 12. Prefer destructuring for props and state 13. Use enums for discrete values that won't change 14. Document complex types with JSDoc commentsFor non-global rules you need to change the alwaysApply rule to be false
—-- description: Guidelines for non-global thingy globs: **/mapView/**/*.tsx alwaysApply: false ---Add a .cursorignore
# Dependency directories node_modules # Complied Output build *.log eslint.xml # Secrets secrets/** # All config files - but we want to keep the folder config/** !.gitkeep # Environment **/*.env !example.env # Large test files tests/*/*.large.json # IDE - VS Code .vscode/ !.vscode/settings.json !.vscode/tasks.json !.vscode/launch.json !.vscode/extensions.json # OS Specific garbage .DS_Store # Reports reportsUpdate your .gitignore
# Ignore files and directories with 'cursor' in the name *cursor*
When you stage git files make sure to ignore your cursor files too (especially if you havent done the .gitignore stuff… Im typically running
git add . ‘:!*cursor*’Specify the mundane task for you cursor agent. I have a workflow that works for this.
For example, if I want to get the agent to fix all the errors from some static checks step that’s failing in a pipeline I will follow this process: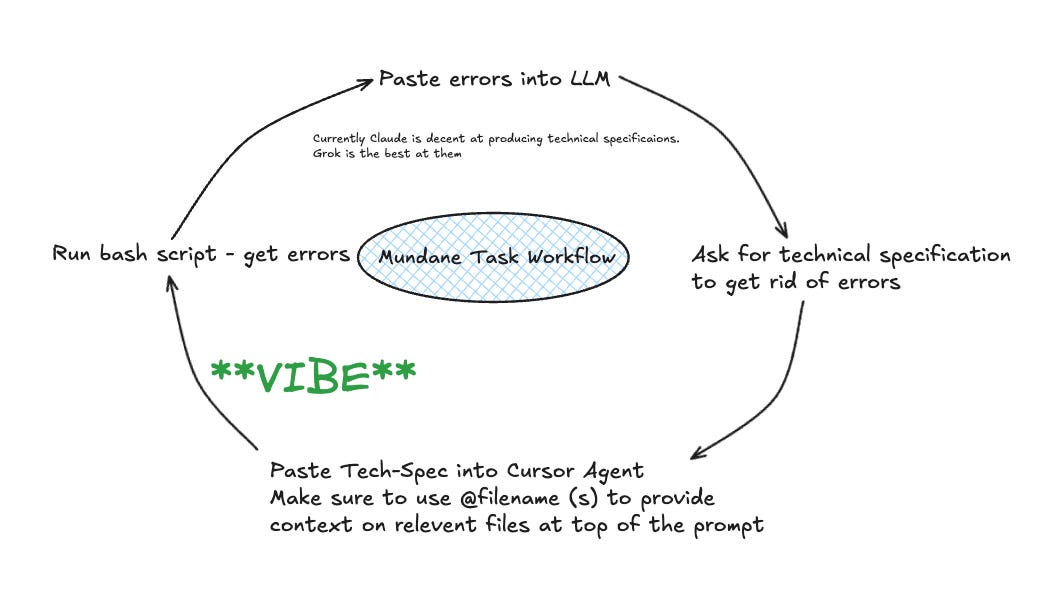
As much as I despise Apartheid-sympathiser and renowned Edgy Nazi FElon Musk, presently Grok (for some reason) is the best at writing tech specs for tasks. Im sure this will change. Claude is OK and on the paid tier you can add a lot of context in Projects. New OpenAI models are dropping and I’ve also heard good things about Gemini 2.5. I have no empirical data to fairly compare these models on these tasks and the cutting edge is highly competitive.
I usually give an LLM some context on the task and code base Im dealing with and ask it to produce a tech-spec that I can feed to my agent.
i.e. I might run a script like this to run my static checks and filter out logs and things that aren’t errors:
#!/bin/bash# This script runs 'yarn static-checks' from the parent directory
# and filters the output to only show linting errors (not warnings).
#
# DEPENDENCIES:
# - Requires 'yarn static-checks' to be defined in the parent directory's package.json
# - Bash or compatible shell with awk installed
#
# USAGE:
# ./scripts/lint-errors.sh # Run and show errors in terminal
# ./scripts/lint-errors.sh > errors.log # Run and save errors to file
# Navigate to the parent directory where package.json is located
cd "$(dirname "$0")/.." || { echo "Failed to navigate to parent directory"; exit 1; }
# Check if yarn and the static-checks script exist
if ! command -v yarn &> /dev/null; then
echo "Error: yarn is not installed or not in the PATH"
exit 1
fi
if ! grep -q "\"static-checks\"" package.json; then
echo "Error: static-checks script not found in package.json"
exit 1
fi
echo "Running yarn static-checks and filtering for errors only..."
echo "=================================================="
echo ""
# Run the static-checks command and pipe it through awk to filter for errors
# The command is run in a subshell to capture its output regardless of exit code
(yarn static-checks 2>&1) | awk '
BEGIN { found_errors = 0; current_file = ""; }
# Store the current filename when we see a line starting with /
/^\/.*/ {
current_file = $0;
next;
}
# Match actual linting error lines (not command errors)
/[0-9]+:[0-9]+.*error/ && !/error Command failed/ {
if (current_file && current_file != last_printed_file) {
print current_file;
last_printed_file = current_file;
}
print $0;
print "";
found_errors = 1;
}
# Print the summary line with error count
/✖.*[0-9]+[[:space:]]+problems/ {
print "Summary:";
print $0;
print "";
found_errors = 1;
}
END {
if (!found_errors) {
print "No linting errors found. Your code is clean!";
}
}
'
echo "Done!"
# Exit with success, even if the linter itself exited with an error
# since we expect that when there are linting errors
exit 0
```
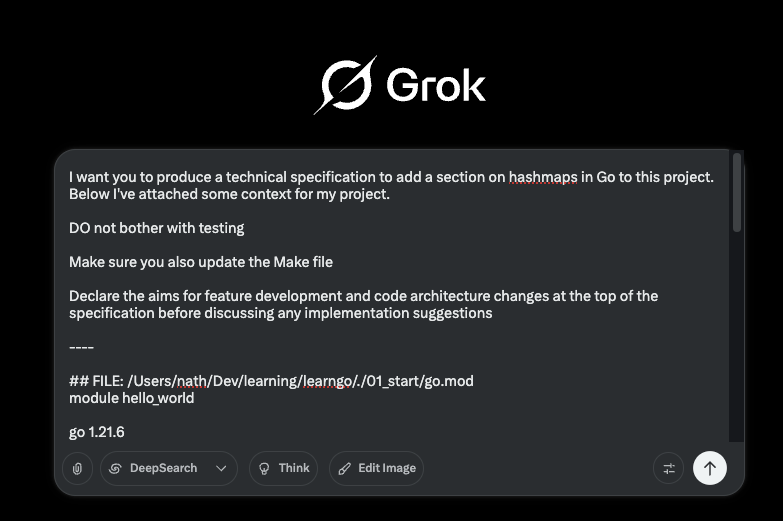
If I run this script `./scripts/static-errors.sh | pbcopy` or xargs whatever if you’re on linux ( my .dotfiles config has an alias for copy that handles both OS’s https://github.com/NathOrmond/dotfiles ) I can paste that output into an LLM with whatever other details I want and ask it to produce a technical specification for the thing I want it to do.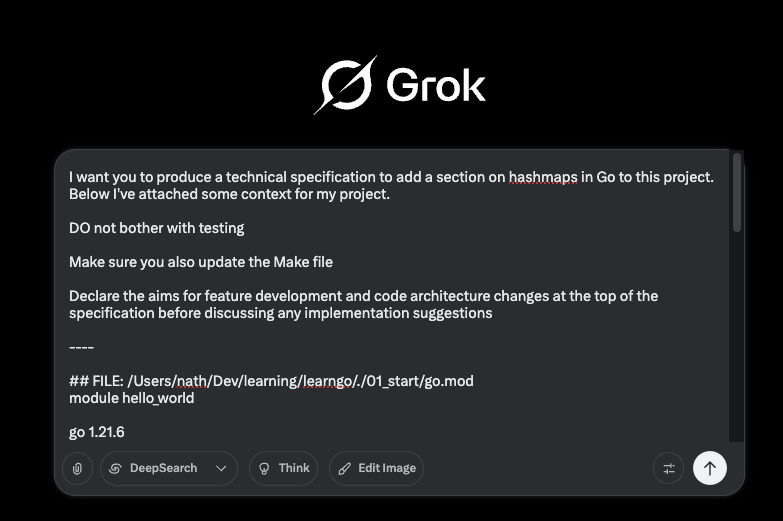
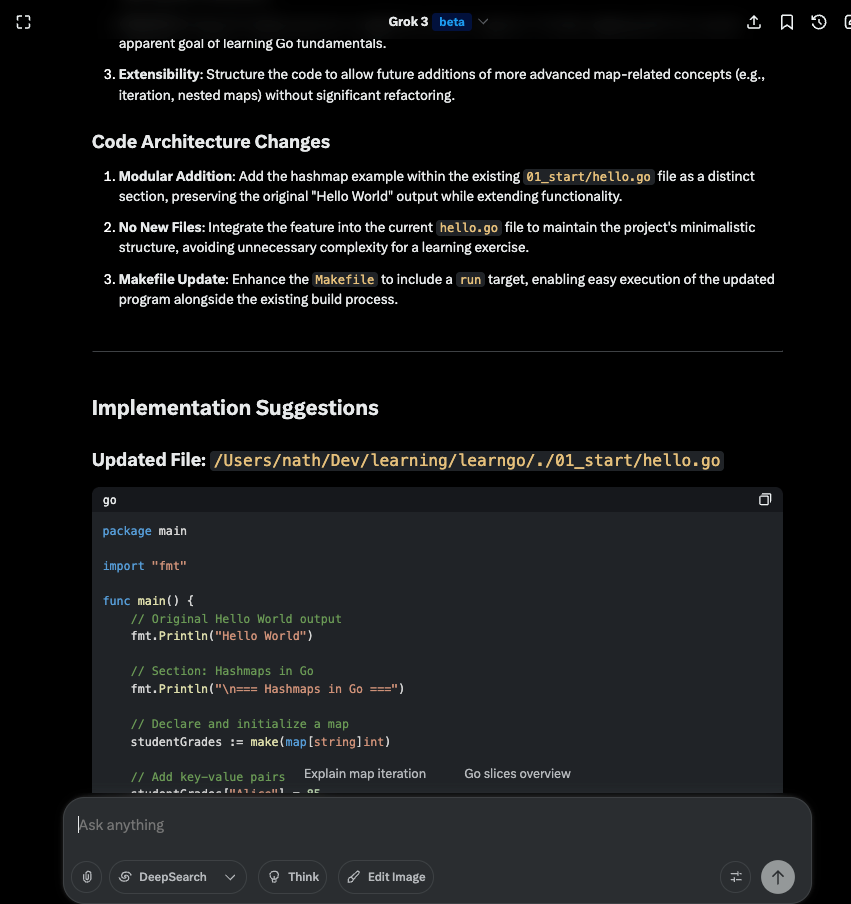
This will give me a tech-spec like: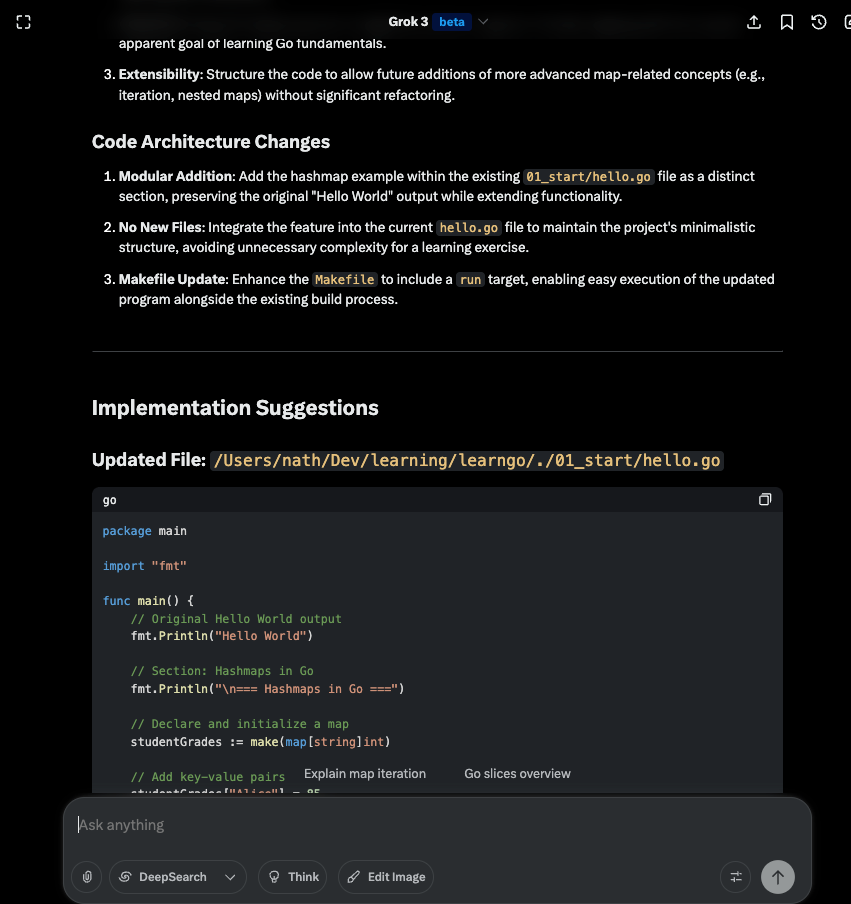
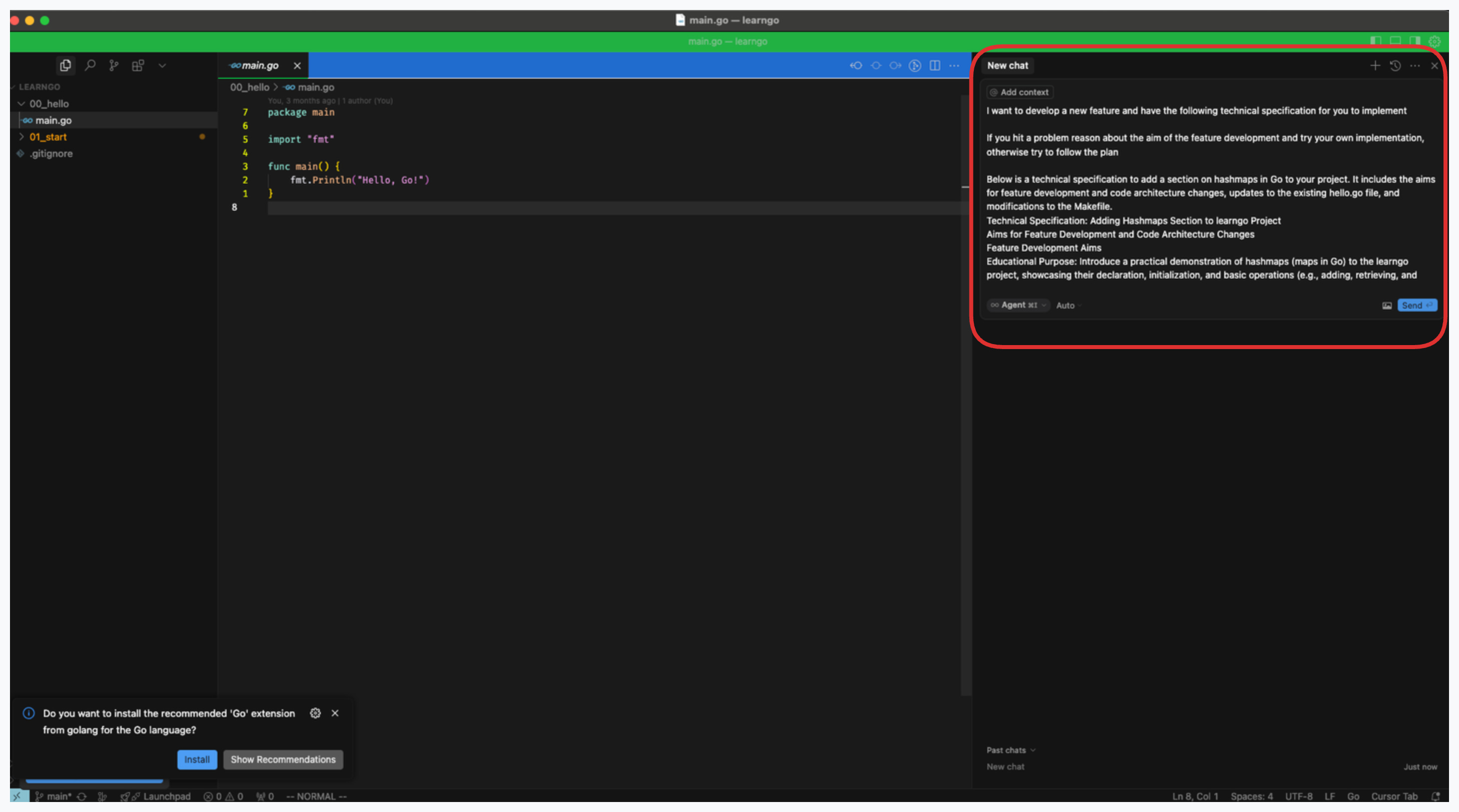
I can then copy this technical specification into the Cursor agent and modify my query adding context.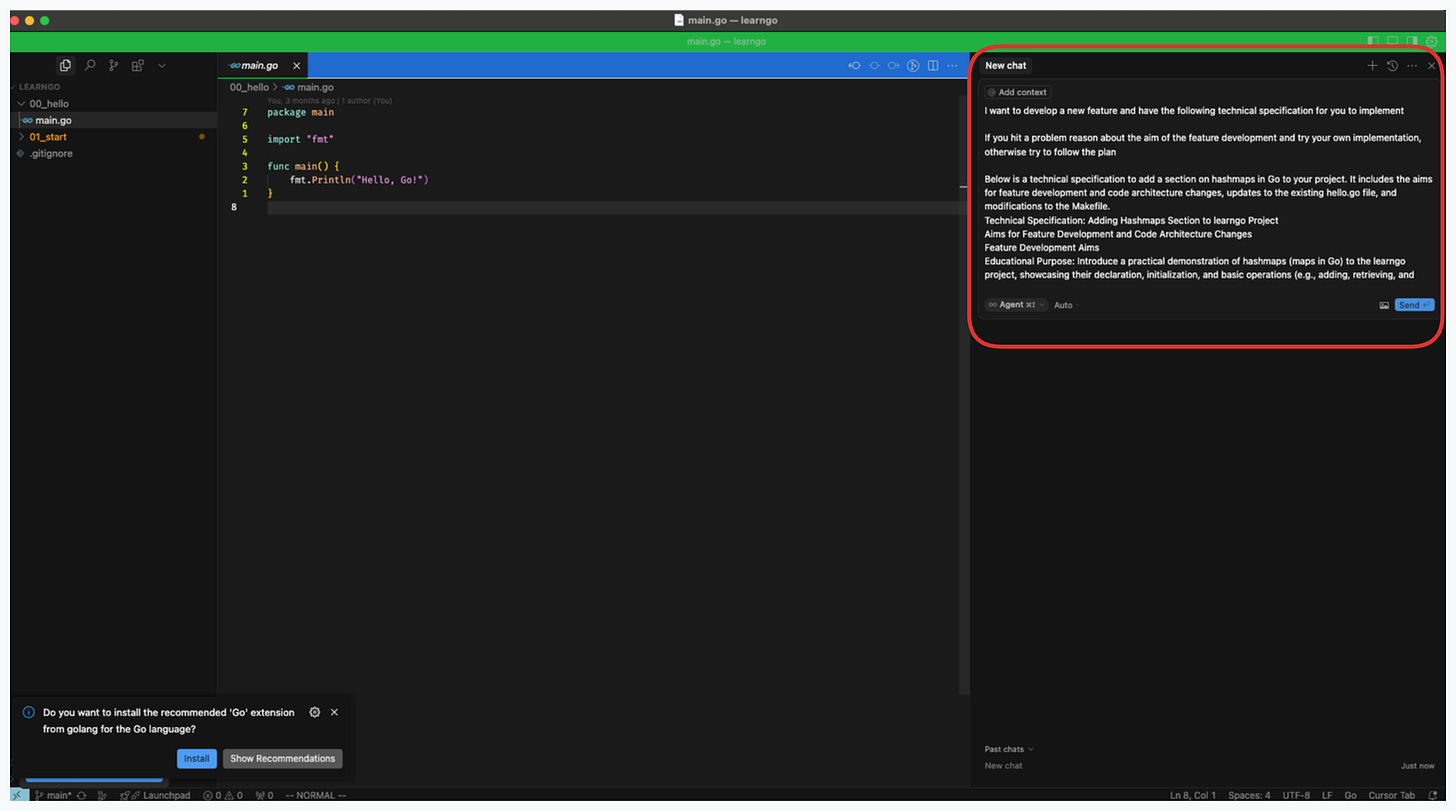
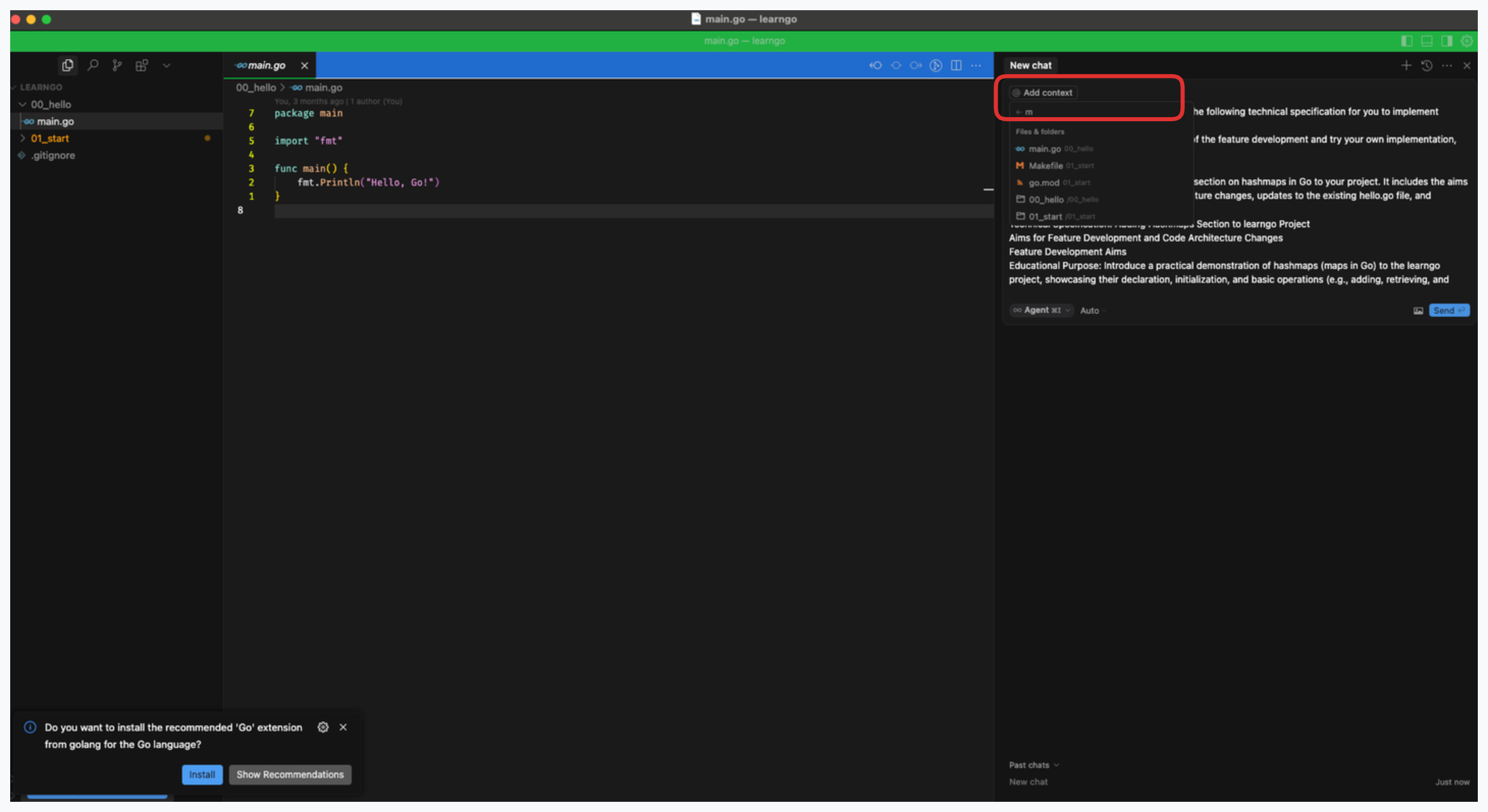
You can click the add context button and select files/folders for context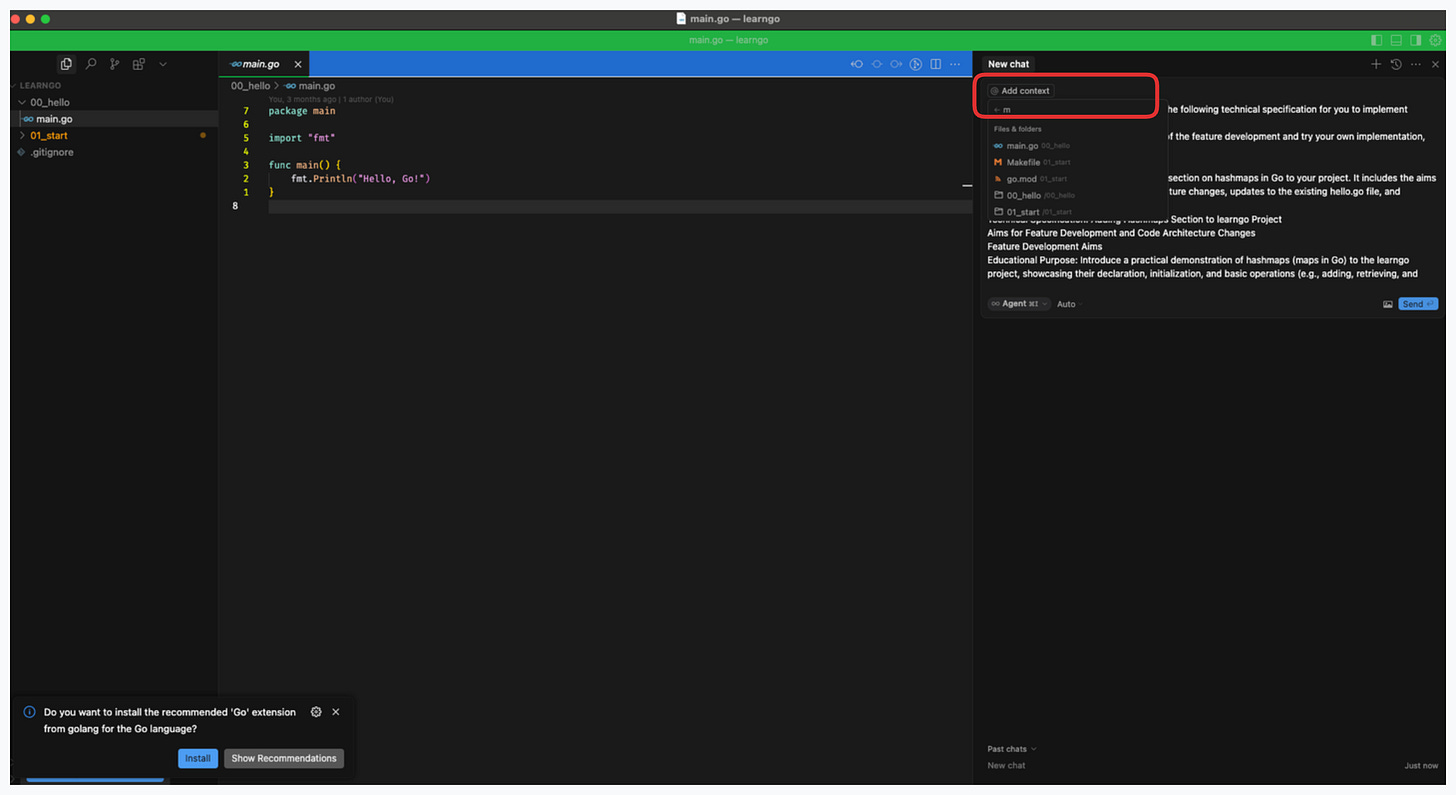
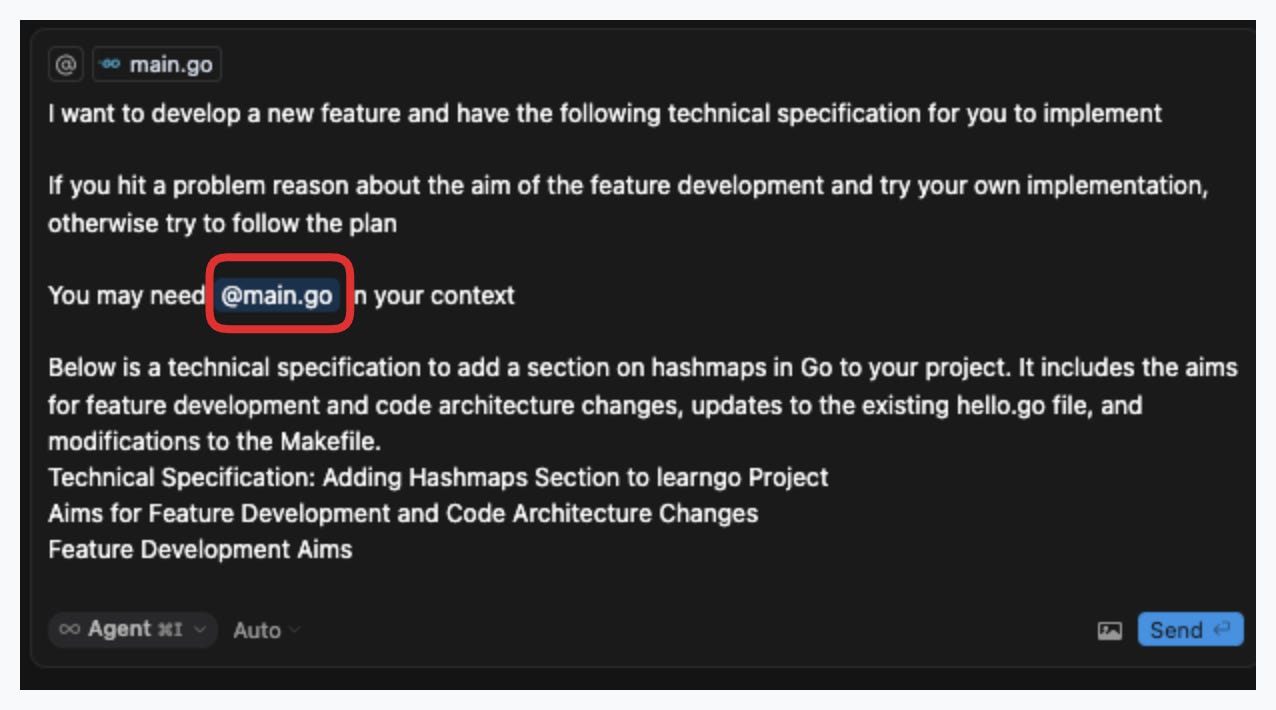
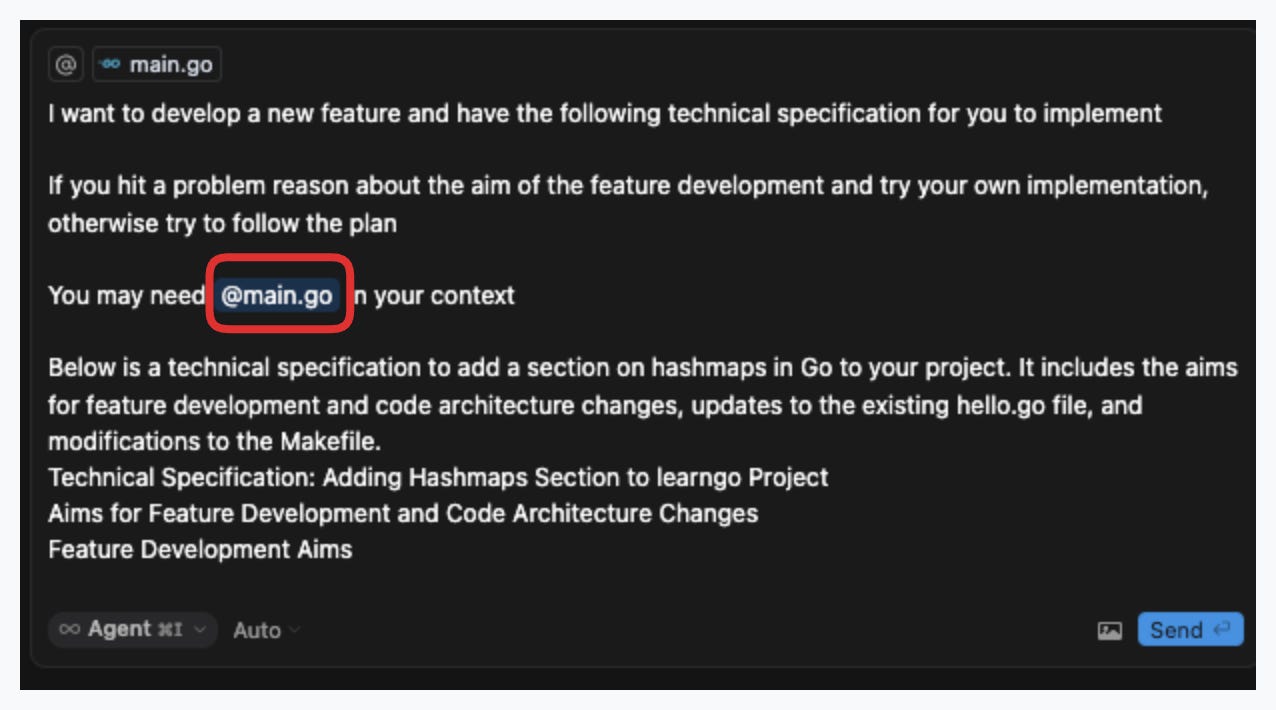
You can also add context by typing ‘@’ in the cursor agent window
Caveats
Multiple queries in the same context can be really bad:
(i) They eat up bajillions of tokens and so you’ll hit your limits fast
(ii) Inherent limitations in the way deep learning models are architected mean they’re kind of bad if they set off on the wrong track.
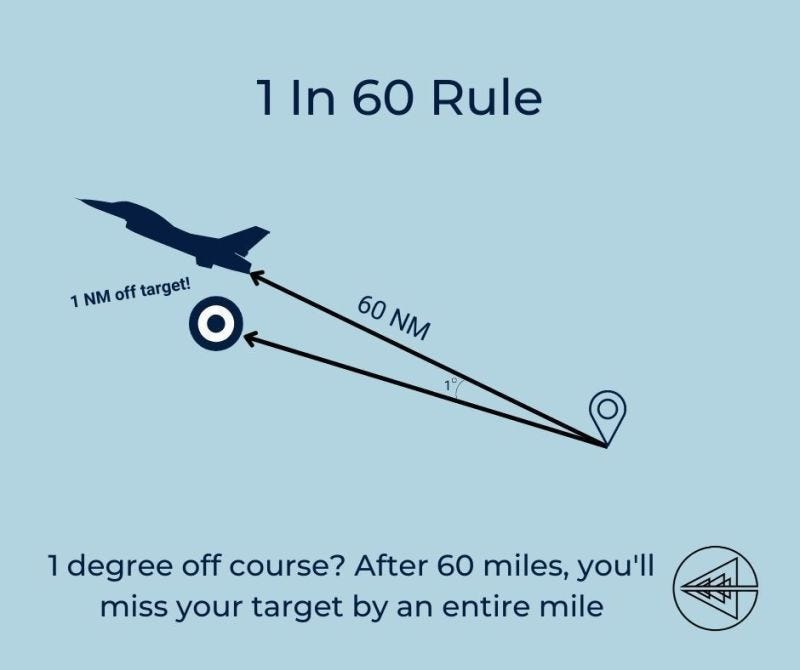
There’s a metaphor in engineering and orienteering that if you’re off by a degree initially it can set you off by miles later on…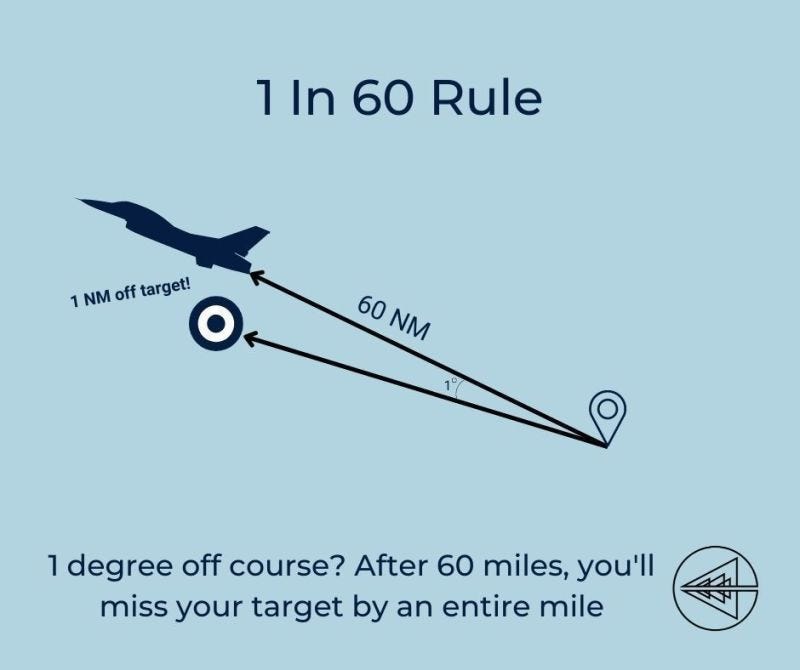
The exact same is true with LLM’s and their context windows. If they don’t “get” the problem you’re trying to solve the more you go on, the further you can get from “fitting” your model to the actual problem you’re trying to solve. In the end you wind up with an agent that’s hallucinating all sorts of nonsense, a ton of tech debt to deal with and a bunch of lost time. These problems get worse the larger the problem is you ask Agents to tackle. Agents are generally quite good on small well defined tasks, and kind of hopeless on intricate large scale tasks with a lot of ambiguity in them.
FINALLY
Validate validate VALIDATE your code.
I swear to god if I catch React Bootcamp dev Edward ‘Big Balls’ Coristine committing his AI slop broccoli trim COBOL into mission critical systems then imma deport him to El Salvadore
The power of these tools is no substitute for good software engineering practices and principles, and these are difficult. When compilers and high-level languages were invented, we had to develop new principles. The same is true with the tools we now have.
Giving cursor, GPT and Claude to the wrong person is like giving a Chimp a machine gun… it’s dangerous. And worse, “odd” code can slip into your repo over time and lead to peculiar behaviour that is hard to reason about and debug because it was written by.. a soulless high degree polynomial function that generates tokens and not a human MADE IN THE IMAGO DEI /s



It’s worth being transparent around and experimenting with best practices for these tools. On the other hand, don’t be a boomer and cry about how it’s all rubbish. It isn’t these tools can be incredibly powerful and really enhance productivity. Like anything else, we devs need to learn and hone the right skills and processes to emphasise the benefits and protect against the risks.